








数据结构
总所周知,Lua的Table可以说是最重要的数据类型之一,由他实现很多常用的特性和数据结构比如字典、面向对象等。
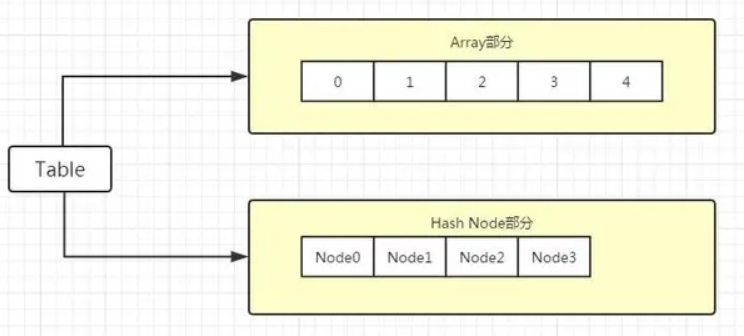
Table分为两部分,分别是数组Array和Hash部分。数组部分主要是存储下标从1开始的连续不为空的节点内容,这样可以通过数组随机存取的特性快速的查找数据。如果是中间断开部分会存到Hash部分,Hash部分是存储各种类型的离散数据,本文主要关注hash部分的存储。
哈希冲突
在Lua中,Table的Hash部分使用了一种开放地址哈希法来解决哈希冲突。具体来说,当Table中需要存储一个新的键值对时,Lua会首先计算出该键的哈希值,并将其转换为Table中的一个数组索引。如果该索引位置已经被占用,Lua会使用一定的探测算法来寻找下一个可用的空位置。探测算法的具体实现是根据索引位置和一定的步长序列来计算下一个位置,直到找到一个空位置为止。
Lua中的探测算法有两种实现方式,分别是线性探测和双重哈希探测。线性探测是一种简单的探测算法,它按顺序检查下一个位置,直到找到一个空位置。双重哈希探测则是使用两个不同的哈希函数来计算下一个位置,这样可以减少冲突的概率。
除了开放地址哈希法,Lua中的Table还使用了一个叫做拉链法的解决哈希冲突的方法。当哈希冲突发生时,Lua会在该索引位置上创建一个链表,将具有相同哈希值的键值对都放到这个链表中。这种方法相对于开放地址哈希法来说更加灵活,但也需要额外的空间来存储链表节点。
具体如何解决冲突,后面有详细的实例来展示。
初始化
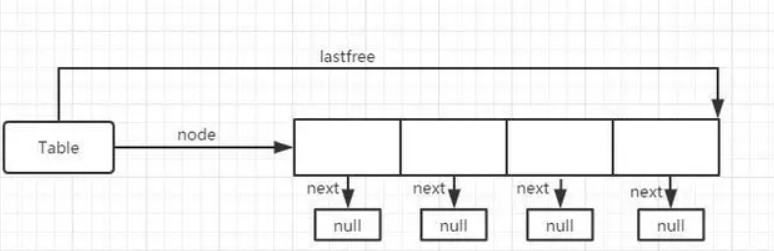
对于一个Table初始化的时候,如果是空表,即Array和Hash部分长度都为0,Hash表的最小长度为2的0次幂,且一定是2的整数次幂为了减少空表的维护成本,Lua在这里定义了一个不可改写的空哈希表:dummynode。让空表被初始化时,node域指向这个dummy节点。它虽然是一个全局变量,但因为对其访问是只读的,所以不会引起线程安全问题。
假设我们现在初始Hash部分长度为2,2的指数为4,因此会生成长度为4个节点,每个节点内容都为空,next也置为空(实际作用是作为一个相同hash值的key的链表)
总之,在构造哈希函数时,Lua使用了一种简单的哈希函数:将键(key)的地址(即内存地址)转换成一个无符号整数,并对哈希表的大小取模,从而得到元素在哈希表中的位置。这种哈希函数可以快速计算哈希值,但是在某些情况下可能会导致较高的冲突率。因此,Lua在哈希表的大小发生变化时,会重新计算所有元素的哈希值,并重新散列。这种方法可以保证哈希表的性能和均匀性。
插入
- 现在我们要给Table赋值,例如执行:tb["k0"]="v0",即key为"k0",value为:"v0",我们需要做以下的事情:
- 根据key去查找有没有已经存在的。
- 如果有,更新一下value即可。(显然,现在是没有的)
- 如果没有,需要newkey(hash部分最核心的函数),newkey过程:
- 检查需要查找的key的mainposition是否为空(mainposition是根据key的hash值计算得出来一个Node)
- 如果mainposition是可用并且是空的(在t->node指向的内存空间内找到没有占用的Node),就使用它,设置key和value。(这个时候,4个节点都为空,可以设置了)。假设它找到的位置是第3个,此时结构图为下图。
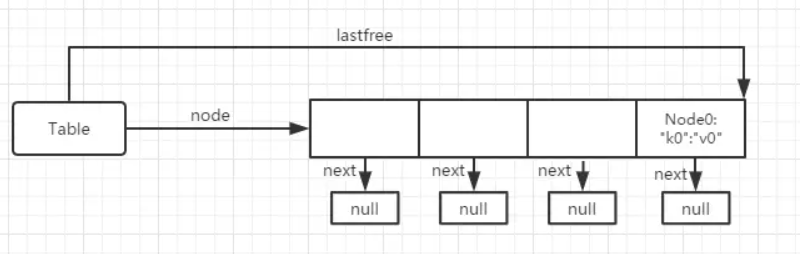
- 现在赋值:tb["k1"]="v1",通过key查找mainposition的时候,回到刚上一步newkey的过程。
- 此时假如查找"k1"的mainposition和"k0"的一样时候,这时"k1"发现自己的mainposition被占用了。
- 既然被占用了,那我们通过lastfree从后往前一个一个找。根据此时内存结构,应该找的到下标为2的节点,同时lastfree会停留在这里。
- 既然"k0"占了"k1"的位置,"k1"要想办法协调了,要检查"k0"的mainposition到底是不是现在的位置(计算两个key通过hash计算出来的mainposition一样),如果不是就需要让位了,如果是则通过链表连接起来,把"k1"指向"k0"的下一个节点,再把“k0”的next指向“k1”,此时内存结构图为下图。
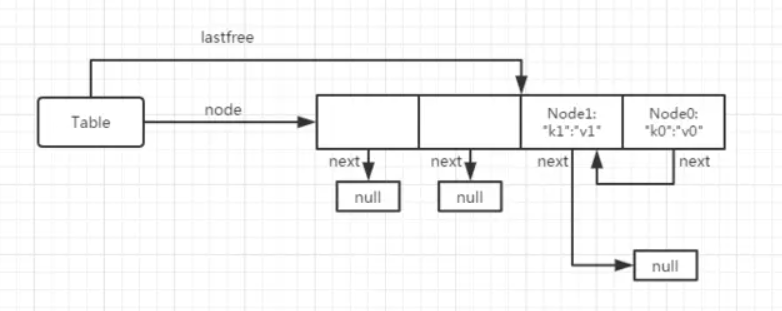
- 再赋值多一次,tb["k2"]="v2"。目前的情况是:k0是在自己的mainposition上面,k1不是在自己的mainposition。
- 此时,“k2”计算得出来,“k1”所在的节点是"k2"的mainposition,因此k1就需要让位置了。
- 需要先找到一个freepos,通过lastfree继续向前找,找到下标为1的节点,lastfree此时停留在1的位置。
- 找到位置然后让"k1"自己搬过去空位置去,同时让“k0”的下一个继续指向“k1”所在的位置,这样子,把"k1"的mainposition腾出来了。此时内存结构图为下图。
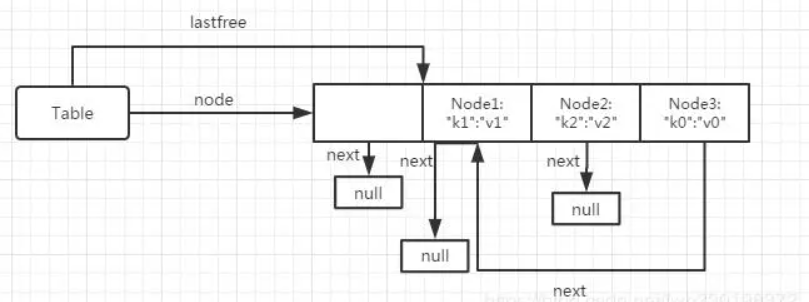
- 假设现在赋值,tb["k3"]="v3",刚好"k3"毫无差池地落入了第0个里,刚好填满
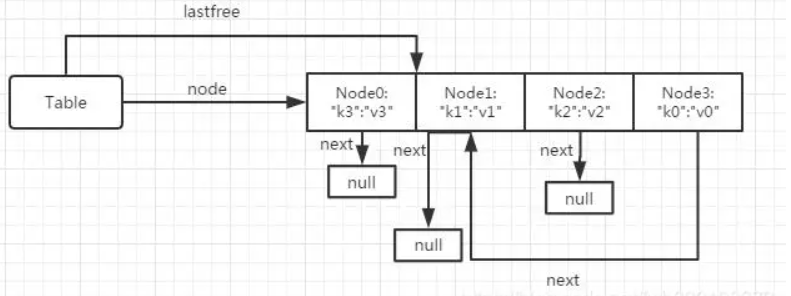
扩容
再来赋值一个tb["k4"]="v4",发现一个位置都没有了,需要进行扩容。
扩大的规则是:根据当前lsizenode来增加,比如当前指数为2,2的2次方,为4。在这个基础上指数增加一级,就是lsizenode即为3了,变成2的3次,扩容后数量为8,即为rehash。
rehash的过程是:
- 先分配一块新的内存块,像这里的情况是分配了长度为8的节点大小内存块。
- 此时,要把旧的迁移过来新内存块。但是,它并不是按顺序一个一个对位拷贝的,遍历每一个节点的时候,需要重新去找一次mainposition,所以分配前后的位置可能会不一样(它和Array部分不一样,Array部分是直接一对一,位置不变地拷贝的)。
- 这个时候有rehash之后可能是下图,因为mainposition需要重新找

rehash以后,再重新去找"k4"的位置,重复之前插入的逻辑。
删除
lua中并没有删除操作,而仅仅是把对应键位的值设置为nil。
表的迭代部分
遍历table主要是ipairs和pairs两个函数,ipairs遍历的是table的数组部分,pairs遍历的是table的数组+hash部分。
这两个函数都会在vm内部临时创建出两个变量state和index,用于对lua表进行迭代访问,每次访问的时候,会调用luaH_next函数,在大多数其它语言中,遍历一个无序集合的过程中,通常不允许对这个集合做任何修改。即使允许,也可能产生未定义的结果。
在lua中也一样,遍历一个table的过程中,向这个table插入一个新键这个行为,将无法预测后续的遍历行为。但是,lua却允许在遍历过程中,修改table中已存在的键对应的值。由于lua没有显式的从table中删除键的操作,只能对不需要的键设为空。
获取长度
获取lua的table的长度#定义只对Array部分有效,用二分法找到一个索引i,使得t[i]存在而t[i+1]为nil,就把i作为table的长度返回
总结
- 在对table操作时,尽量不要触发rehash操作,因为这个开销是非常大的。在对table插入新的键值对时(也就是说key原来不在table中),可能会触发rehash操作,而直接修改已存在key对于的值,不会触发rehash操作的,包括赋值为nil。
- 在遍历一个table时,不允许向table插入一个新键,否则将无法预测后续的遍历行为,但lua允许在遍历过程中,修改table中已存在的键对应的值,包括修改后的值为nil,也是允许的。
- table中要想删除一个元素等同于向对应key赋值为nil,等待垃圾回收。但是删除table一个元素时候,并不会触发表重构行为,即不会触发rehash操作。
- 为了减少rehash操作,当构造一个数组时,如果预先知道其大小,可以预分配数组大小。在脚本层可以使用local t = {nil,nil,nil}来预分配数组大小。在C语言层,可以使用接口void lua_createtable (lua_State *L, int narr, int nrec);来预分配数组大小。
- 注意在使用长度操作符#对数组其长度时,数组不应该包含nil值,否则很容易出错
资料参考
Lua源码之Table-细说Hash部分(主要来源于这篇文章)
浅析C# Dictionary实现原理(拓展:介绍同样使用Hash算法的C#字典)


 加油
加油

